[weekly] [nb] 웹 개발 시작하기(2)
HTTP로 서버에 데이터를 보내는 방식에 대해 실제 웹 서비스를 예시로 리퀘스트, 리스폰스를 설명해 주세요. (크롬 개발자 도구를 활용합니다.)
openlibrary
이번에 테스트로 사용한 서비스는 open library 다.
instagram 이나 여러 sns 서비스도 많지만, 대부분 로그인을 강제하는 경우가 많아서 선택지에서 제외했다. sns 를 하지 않아서, 회원가입 하는게 귀찮기도 하고.
openlibrary 를 추천하는 이유
1. openlibrary 웹 페이지는 이 학습을 하기에 적절한 레이아웃을 가지고 있다.
개발자 도구 상태의 open library 는 아래와 같다.
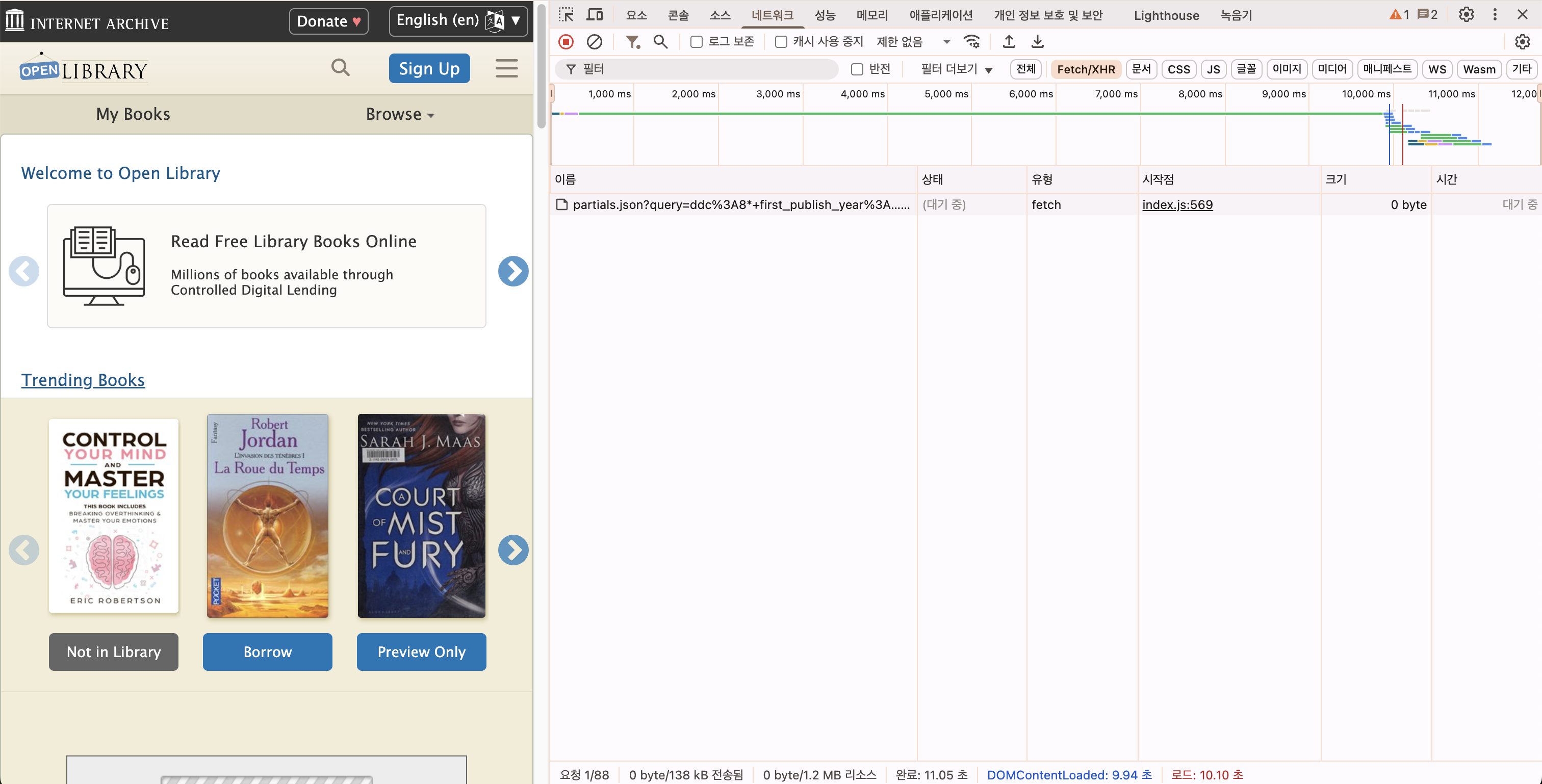
openlibrary 는 영역이 좁아들면 자동으로 모바일 환경에 맞춰서 레이아웃을 수정한다.
물론, 요즘에는 이렇게 대응하는 웹서비스는 많아서 그렇게 특별한 건아니다.
대신 openlibrary 는 ui가 심하게 단순하고 깔끔해서 요청하는 리소스가 상대적으로 많지 않아서 구분하기 좋다.
instagram 이나 airbnb 같은 서비스를 들어가보면, 그냥 평범한 home 화면인데도 요청(request) 가 수십개는 존재한다. 그리고 그 수십 개의 요청(request)이 무엇을 위해서 서로 왔다 갔다 하는지 알기가 너무 힘들다.
우리가 상호작용한 부분으로 발생한 응답(request)과 요청(response) 가 적어도 뭔지는 알아야 학습이 될꺼 아닌가?
2. 느리다
느린게 대체 뭐가 좋냐고 말할 수 있는데, 요청(request) 과 응답(response) 이 너무 빠르면 어떤 순으로 순차적으로 진행되었는지 체감하기가 어렵다.
상기했던 airbnb 같은 서비스 처럼 수십개의 요청(request)과 응답(response) 이 무엇을 위해서 서로 왔다 갔다 하는지 알기가 힘든 상황에서, 그 속도마저 빠르면 내가 하나를 보는 사이에 운 나쁘면 또 수십개가 쌓인다.
javascript 검색
검색 창에 'javascript' 를 입력하고 enter 를 누른다. 그러면 약 3초(!)의 시간을 기다리면 검색 결과 문서를 볼 수 있다.
지금 같이 인터넷이 빠른 환경에서는 믿기지 않을 속도다!
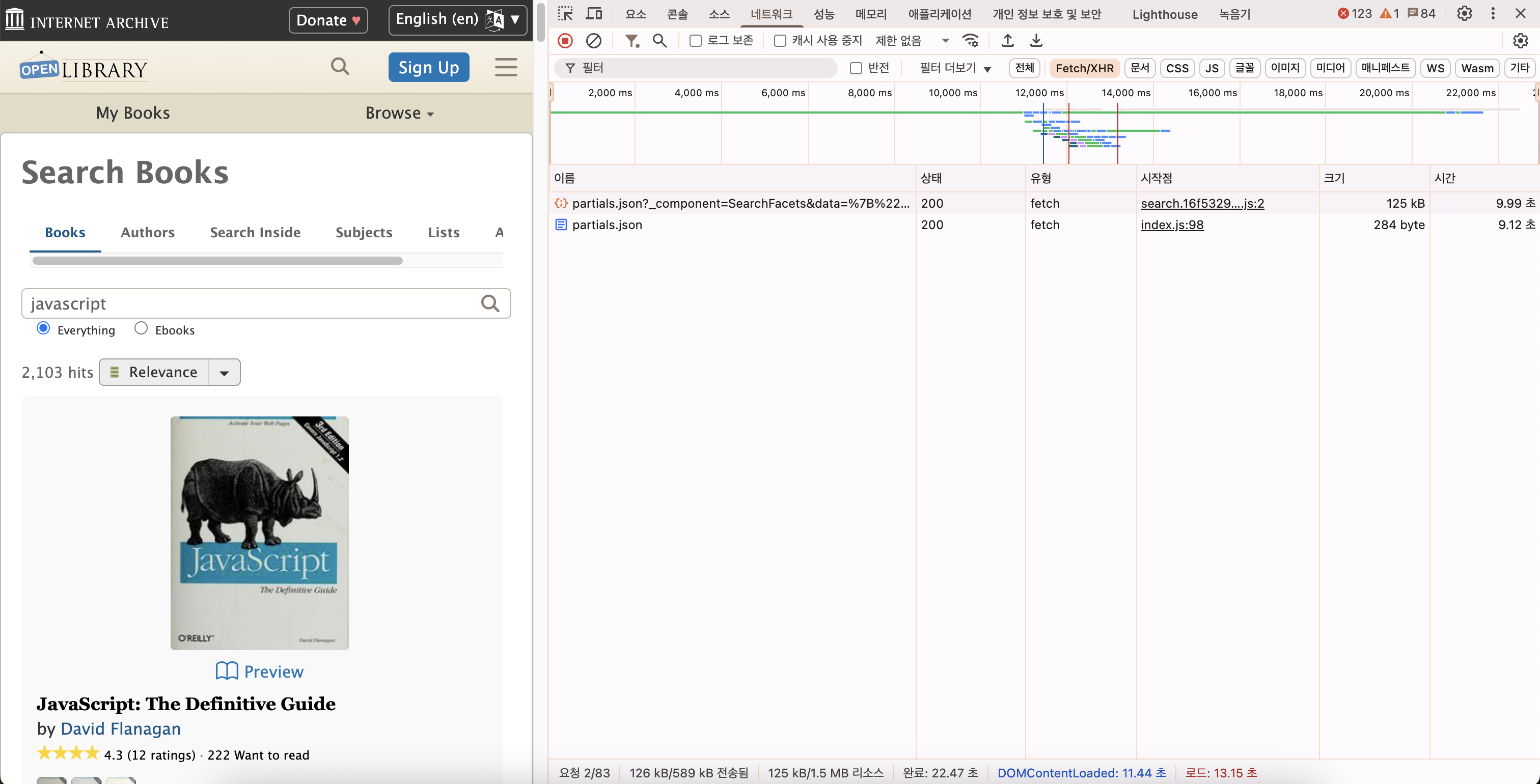
결과가 나온 문서의 주소창을 보면 우리가 넣은 검색 단어를 바탕으로 한 쿼리가 들어가 있는 것을 볼 수 있다.
https://openlibrary.org/search?q=javascript&mode=everything
쿼리 분석
-
url : https://openlibrary.org/
대체로 url은 보통 우리가 들어와 있는 홈페이지의 url 동일하다. -
parameter : search
parameter 는 기능별로 나뉘어지는 경우가 많다. 이번에는 search 하는 parameter 라는 뜻이다. -
query : ?q=javascript&mode=everything
query 는 언제나 ?로 시작한다.
query 내에서 사용하는 scheme 은 딱 정해진 것은 없다. 표준처럼 쓰이는 표현은 많지만, 어디까지나 scheme 은 백엔드 개발자의 선택에 따라 달라진다. 문서화만 잘 된다면 크게 문제는 없다.
단, q 는 query 의 약자로, 뜻 그대로 검색어가 들어가는 경우가 많다.
[문서] 탭 보기
이건 의외의 소득이었는데, openlibrary 의 홈페이지는 Server Side Rendering 이다!
이게 무슨 말이냐면, 우리가 뭔가 요청(request)를 보내면, 그 결과에 따라 완성된 웹페이지를 응답(response) 한다.
이러한 원리로 openlibrary 서버의 응답(response) 가 느리면, 우리가 보는 openlibrary 웹페이지의 변환도 느려진다.
일반 정보
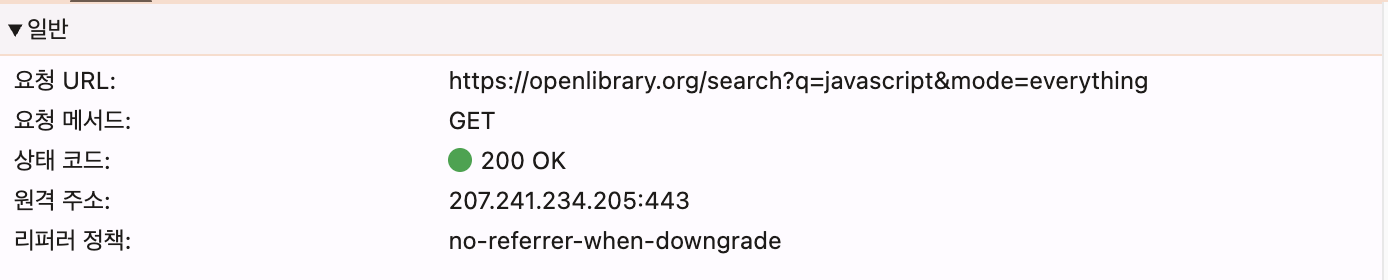
-
메서드에 GET 이라고 적혀있다.
우리가 openlibrary 에 검색을 한 것은 다르게 말하면 openlibrary 쪽에 javascript 랑 관련된 책을 찾아달라고 요청한 것과 같다. 검색을 해서 우리가 얻어야 하기 때문에 이런 요청은 GET 으로 보낸다. -
상태 코드에 200 OK 이라고 적혀있다.
웹 통신에서 200 은 모든 응답과 요청이 올바르게 이루어졌다 는 의미를 가지고 있다.
이 숫자는 아무렇게나 정해진 것은 아니고 아래와 같은 규칙으로 만들어져 있다.코드 의미 1xx 처리중 2xx 성공 3xx 리다이렉션 필요 4xx 클라이언트가 잘못 보낸 요청 5xx 서버 오류 딱히 외울 필요가 있는 것은 아니지만,
- 처리 중
- 성공!
- 응? 안돼? 다시 한번 해봐
- 너가 잘못 보낸 거 아냐?
- 아, 서버가 아픈 듯?
의 순서로 생각하면 편하다.
응답(response) 헤더
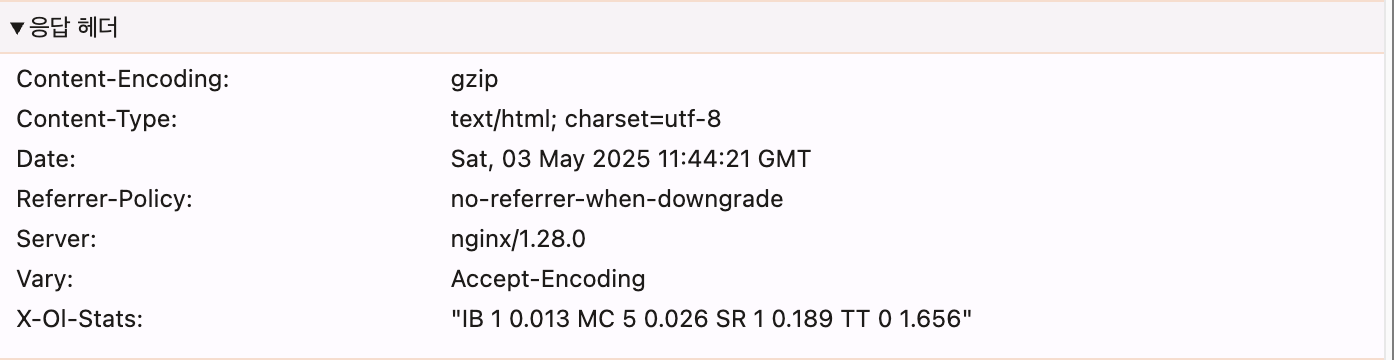 내가 어떤 응답을 받았는 지 기록되어 있다.
내가 어떤 응답을 받았는 지 기록되어 있다.
웹페이지를 받아서 보는 데 직접적으로 관련 있는 것들만 추려서 정리한다.
-
Content-Encoding : gzip
압축파일로 보냈다는 의미다. -
Content-Type : text/html; charset=utf-8
아까 상기했듯이 웹페이지의 코드를 그대로 보내주고 있다. -
Server: nginx/1.28.0
어떤 서버로 보냈는지 표시된다. nginx 라는 웹서버를 사용한 것을 알 수 있다.
요청(request) 헤더
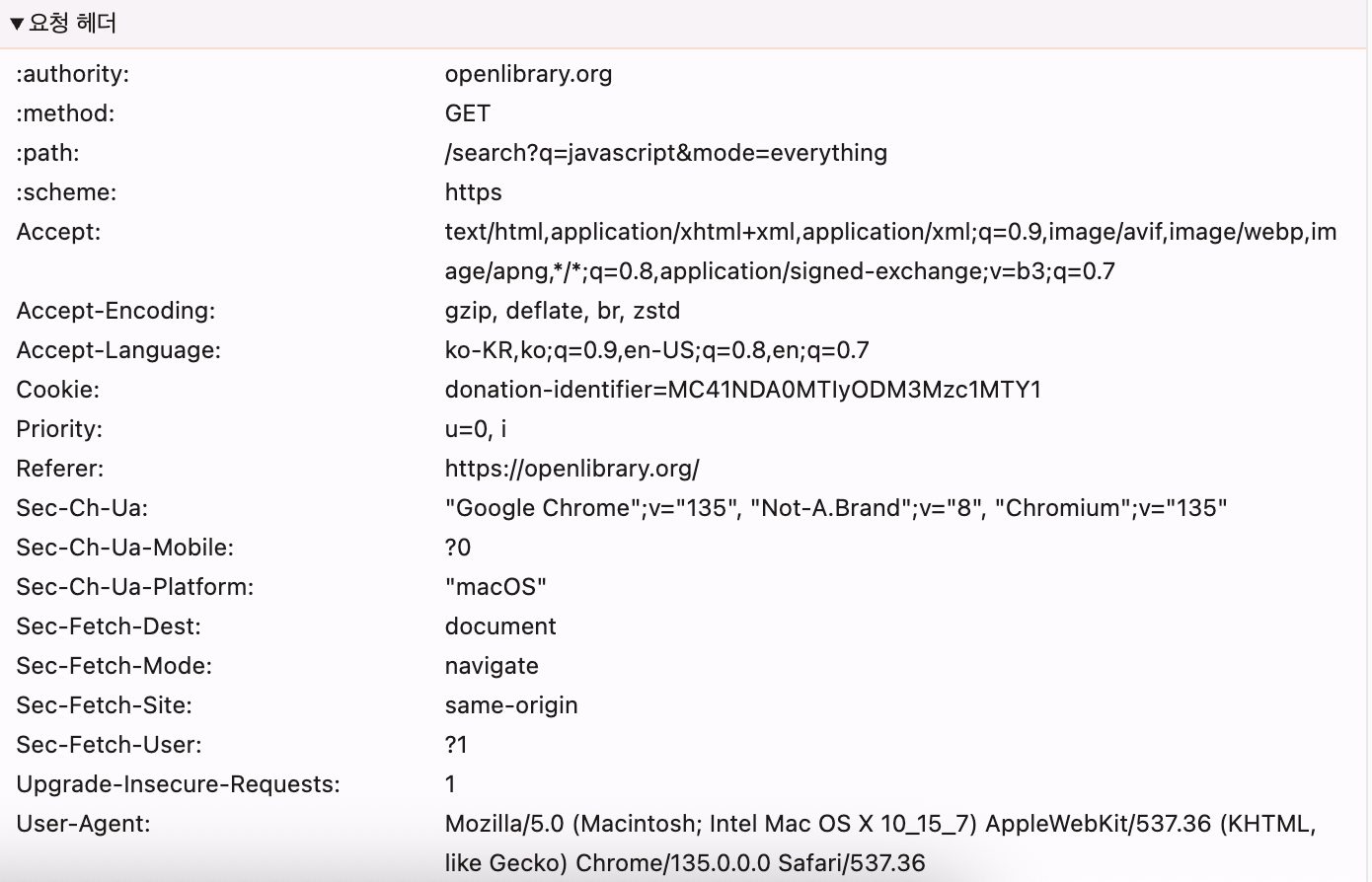 내가 어떤 요청을 보냈었는지도 기록되어 있다.
내가 어떤 요청을 보냈었는지도 기록되어 있다.
-
path: /search?q=javascript&mode=everything
path 는 parameter 와 query 그리고 anchor 로 이루어져있다.
요약하면 search 기능에서 q=javascript&mode=everything 라는 조건으로 무언가를 찾는다는 뜻이다. -
scheme
scheme 은 어떤 형태를 쓸 것인지를 지정한다. 이번 요청에서는 https 로 요청을 보냈다는 것을 알 수 있다.
마무리
openlibrary 의 웹페이지가 심하게 간단해서 서로 요청(request) 와 응답(response) 이 적은 것이 확인하기 좋았다.
이 정도 디자인의 웹페이지라면 나도 만들어 볼 수 있겠는데? 라는 생각도 잠깐 들고.
크롬 개발자 도구..?
weekly report 로 크롬 개발자 도구를 사용해보았는데, 사실 많이 불편했다.
단순히 요청과 응답을 이해하는게 목적이라면 부트캠프 과정에서 배우는 node.js 와 axios 를 사용해서 여러 쿼리를 보내보고 결과를 정리하는 게 더 효율적이었을 거라는 생각이 많이 든다.
node.js 도 좀 더 익숙해졌을테고.
크롬 개발자 도구는 분명 나중에 성능 분석이나 실제 사용할 때 리소스 사용 같은 부분에서는 볼 것 같은데, 굳이 응답과 요청을 보려고 이걸 굳이 써야 하나..? 라는 생각이 많이 들었다.
그냥 터미널에서 명령어 하나면 바로 응답이 오는데 말이다.
그래도 생각보다 크롬 개발자 도구에 많은 기능이 있다는 것을 알게 되었다!